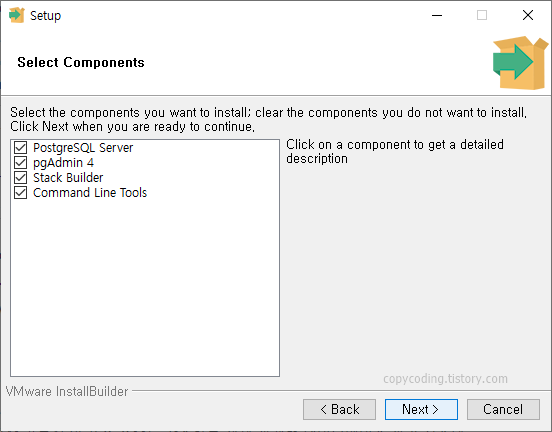
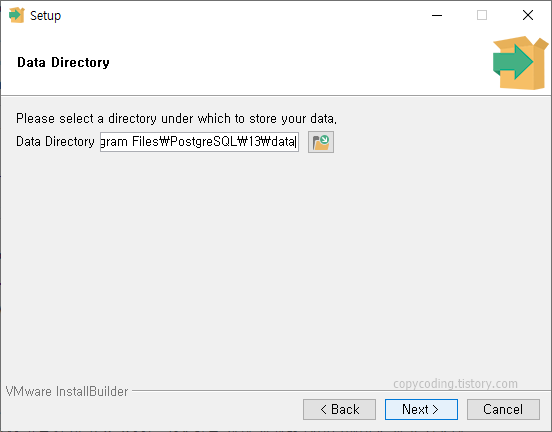
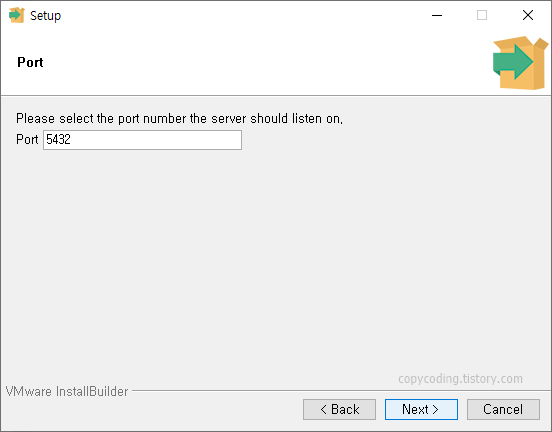
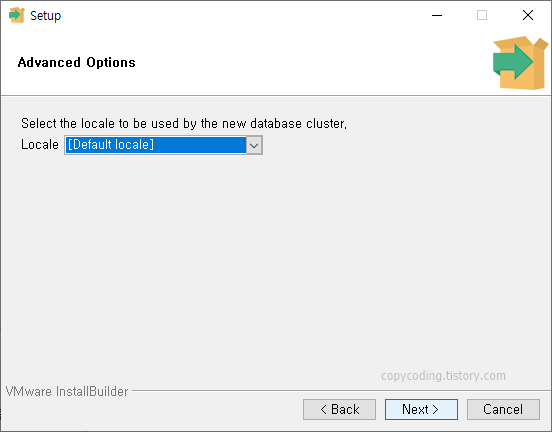
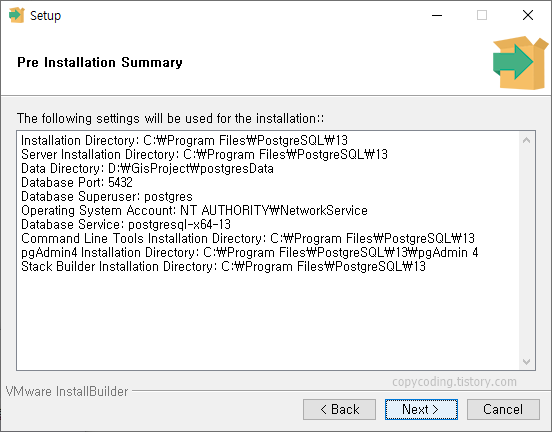
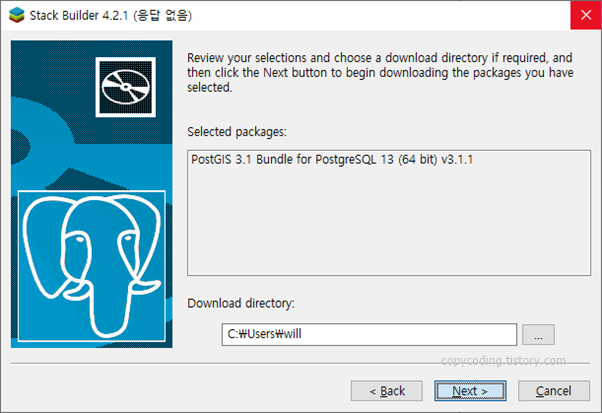
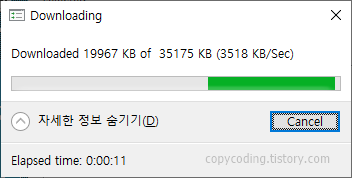
shp 파일 내용을 저장할 database를 PostgreSQL에 생성하기 위해 윈도우 시작 버튼을 클릭 하고
pgAdmin 4를 선택 합니다.
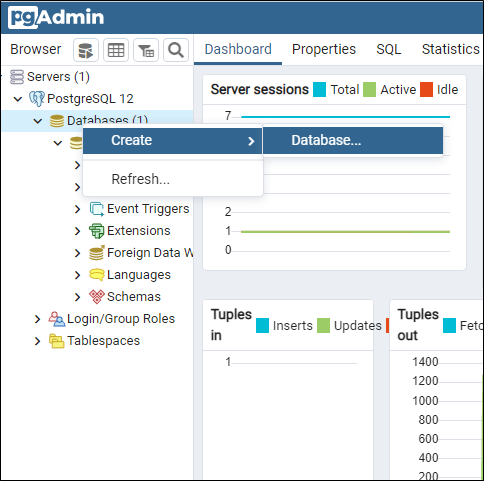
pgAdmin 좌측의 Servers를 확장하여 GIS용 데이터 베이스를 하나 새로 생성을 해서 진행을 하도록 하겠습니다.
Databases에 마우스를 놓고 우클릭 하여 Create > Database... 를 선택 합니다.
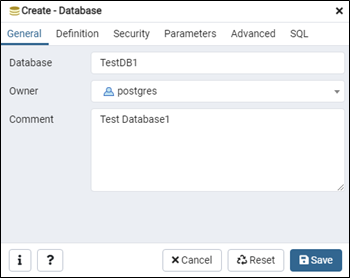
Database 이름을 적당히 입력해 주고 [Save] 버튼을 클릭 합니다.
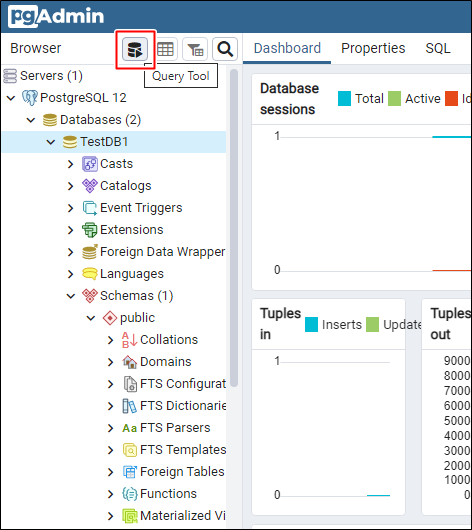
TestDB1 데이터베이스가 생성 되었습니다.
새로 생성된 TestDB1을 선택한 상태에서 상단 아이콘에서 디스크 모양의 Query Tool 아이콘을 클릭 하면 쿼리 입력 창이 나타납니다.
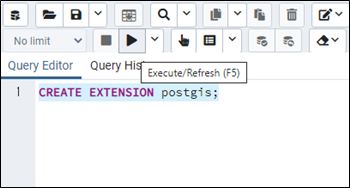
쿼리 입력 창에서 선택된 데이터베이스에 확장 기능을 추가해 주어야 GIS 정보를 담을 수 있는 데이터베이스가 됩니다.
CREATE EXTENSION postgis;
명령어를 입력 하고 실행 버튼 또는 F5 키를 이용하여 쿼리를 실행해 줍니다.
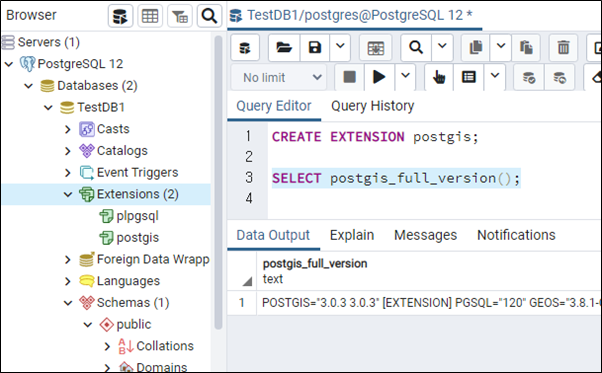
postgis 기능 반영이 잘 되었는지는 다음 명령어를 입력해서 실행해 봅니다.
SELECT postgis_full_version();
쿼리 결과도 잘 나오고 좌측 Extensions에도 postgis가 추가 된 것을 확인 할 수 있습니다.
2. SHP 파일 업로드
shp 파일 업로드는 PostGIS를 통해서 PostgreSQL에 입력합니다.
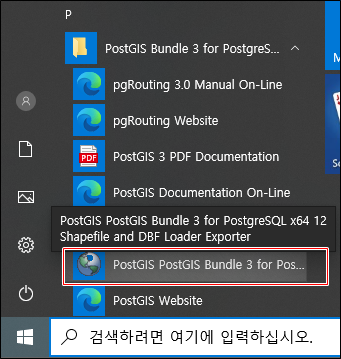
시작 버튼에서 PostGIS를 확장하여
PostGIS Bundle 3 for PostgreSQL ... Shapefile... 을 클릭 합니다.
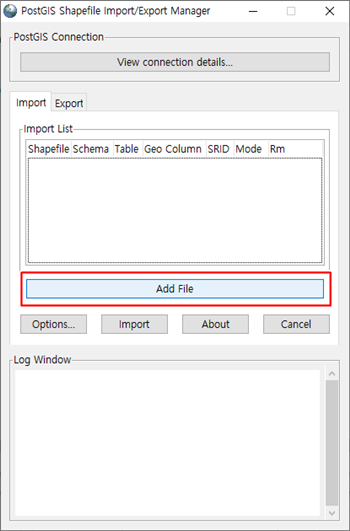
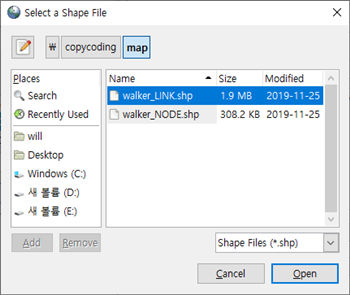
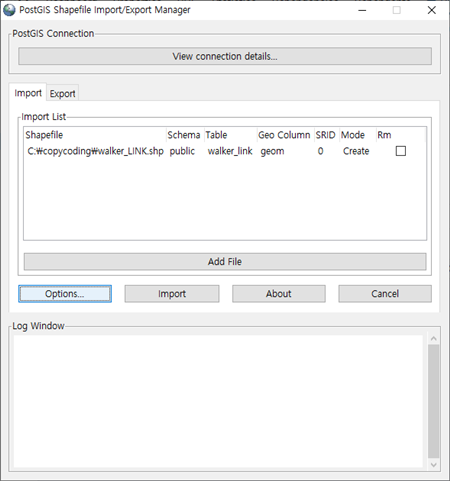
파일을 찾기 위하여 [Add File]을 클릭 합니다.
좌측과 상단에 있는 폴더 기능을 이용하여 SHP 파일이 위치한 곳을 찾아 선택 한 후 [Open] 버튼을 클릭하여 추가해 줍니다.
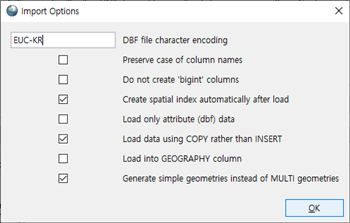
선택한 파일이 추가 되면 만약 파일에 한글이 들어있는 경우 [Options...] 버튼을 클릭 합니다.
여기에서 UTF-8을 EUC-KR로 변경해 주어야 한글이 입력 됩니다.
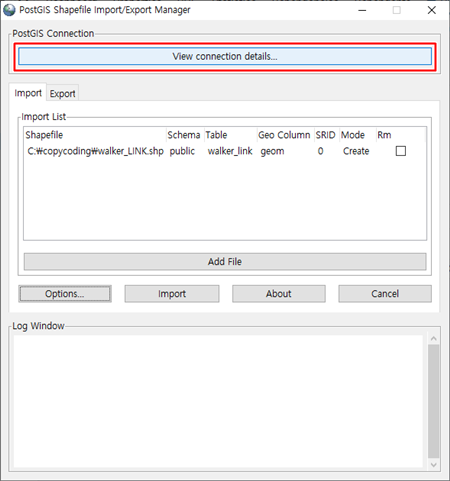
한글이 없다면 상단의 [View connection details...] 버튼을 클릭 합니다.
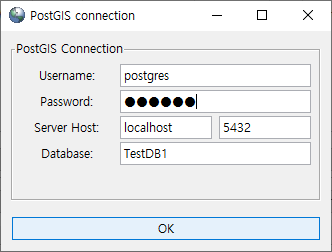
shp파일을 저장할 PostgreSQL에 접속하는 정보를 입력하는 창으로 Database와 기타 필요한 정보를 입력하고 [OK] 버튼을 클릭 합니다.
하단 Log Window에 연결이 성공 되었다고 나오는 군요.
이제 마지막 작업으로 [Import] 버튼을 클릭 합니다.
잠시 후 Log Window에 [Shapefile import completed.] 가 나오면 입력 성공입니다.
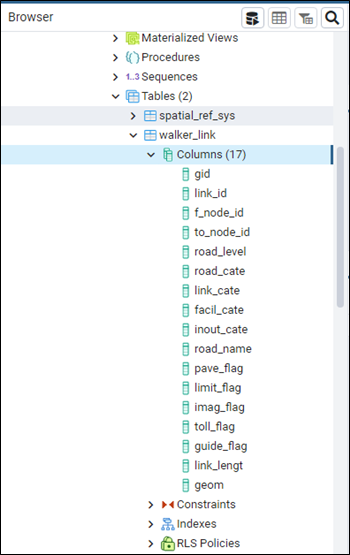
다시 PostgreSQL로 돌아가 DB에서 Table을 확장하면
테이블이 새로 생성이 되고 데이터가 추가 된 것을 확인 할 수 있습니다.
import시 오류가 발생 한다면 shp 파일이 위치한 폴더 명에 한글이 있거나 shp 파일 명에 한글이 있는 경우 오류가 발생 하니 꼭 영문으로 해야 하고 shp 파일 내부에 한글이 있다면 options에서 EUC-KR로 해주면 별 문제없이 import 할 수 있습니다.
예전 Postgresql 버전을 변경하기 위해 윈도우 10에 설치해 보았습니다. 그냥 프로그램을 다운받아 설치하면 되는데 여러 번 설치를 해야 하는 상황이라 매번 검색을 하기 귀찮아 설치 매뉴얼을 만들었습니다. 어려운 부분은 없지만 그래도 보면서 작업 하면 시간이 단축되더군요.
지난번 “[SQL 개발자] SQL 기본 자격증 시험 요약”에 이어서 SQL 활용에 대해 요약을 해보았습니다.
아래 내용은 SQL 개발자 자격증에 대한 서적 중 [이기적 SQL 개발자]를 참고하여 요약을 하였습니다.
SQL 기본에서는 TABLE을 하나만 사용하여 개념을 배울 수 있었다면 활용에서는 테이블들을 조합하여 다양한 결과를 얻을 수 있는 방법을 학습 하게 됩니다.
1. JOIN(조인)
1.1 EQUI Join(등가 조인)
1) EQUI Join(등가 조인)
두 개의 Table 간에 일치하는 Column을 조인 한다.
조인의 가장 기본은 교집합을 만드는 것.
조인은 여러 개의 릴레이션을 사용해서 새로운 릴레이션을 만드는 과정.
SQL> SELECT EMPNO, ENAME, SAL, DEPTNO 2 FROM EMP; EMPNO ENAME SAL DEPTNO ------- -------- ------ ------- 7369 SMITH 800 20 7499 ALLEN 1600 30 7782 CLARK 2450 10 7788 SCOTT 3000 20 7839 KING 5000 10 7902 FORD 3000 20 7934 MILLER 1300 10
SQL> SELECT DEPTNO, DNAME, LOC 2 FROM DEPT; DEPTNO DNAME LOC -------- ------------- -------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON
EQUI 조인은 “=”을 사용해서 두 개의 테이블을 연결 한다.
SQL> SELECT EMPNO, ENAME, SAL, EMP.DEPTNO, DNAME, LOC 2 FROM EMP, DEPT 3 WHERE EMP.DEPTNO = DEPT.DEPTNO; EMPNO ENAME SAL DEPTNO DNAME LOC ------- -------- ------- -------- ------------- ---------- 7369 SMITH 800 20 RESEARCH DALLAS 7499 ALLEN 1600 30 SALES CHICAGO 7782 CLARK 2450 10 ACCOUNTING NEW YORK 7788 SCOTT 3000 20 RESEARCH DALLAS 7839 KING 5000 10 ACCOUNTING NEW YORK 7902 FORD 3000 20 RESEARCH DALLAS 7934 MILLER 1300 10 ACCOUNTING NEW YORK
2) INNER JOIN
EQUI Join 과 동일한 결과를 얻을 수 있으며 INNER JOIN은 Where절이 아닌 From 절에서 ON 문을 이용하여 Join 한다.
SELECT * FROM EMP INNER JOIN DEPT ON (EMP.DeptCd = DEPT.DeptCd);
3) Hash Join(해시 조인)
- 선행 테이블을 결정하고 선행 테이블에서 주어진 조건에 해당하는 행을 선택 한다.
- 해당 행이 선택되면 조인 키를 기준으로 해시 함수를 사용해서 해시 테이블을 메인 메모리(Main Memory)에 생성하고 후행 테이블에서 주어진 조건에 만족하는 행을 찾는다.
- 후행 테이블의 조인 키를 사용해서 해시 함수를 적용하여 해당 버킷을 검색 한다.
4) INTERSECT 연산
두 개의 테이블에서 교집합 측 공통된 column을 조회 한다. DEPT 테이블의 40은 제외된다.
SQL> SELECT DEPTNO FROM EMP 2 INTERSECT 3 SELECT DEPTNO FROM DEPT; DEPTNO ---------- 10 20 30
1.2 Non-EQUI JOIN (비등가 조인)
두 개의 테이블을 조인하는 경우 등가(“=”)를 사용하지 않고 비등가(“>”, “<”, “>=”, “<=”) 등을 사용 하여 일치하지 않는 값을 구하는 조인 방식.
1.3 OUTER JOIN
OUTER JOIN은 LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN이 있다.
1) LEFT OUTER JOIN
LEFT OUTER JOIN은 왼쪽 테이블을 기준으로 해서 비교조건과 동일한 값을 오른쪽 테이블에서가져와 뒤에 붙여주는 형태의 작업 이다. 동일한 값이 없다면 NULL이 붙는다.
SQL> SELECT * 2 FROM DEPT LEFT OUTER JOINEMP 3 ONDEPT.DEPTNO = EMP.DEPTNO; DEPTNO DNAME EMPNO ENAME JOB SAL DEPTNO -------- ------------ ------- -------- ----------- ------- -------- 20 RESEARCH 7369 SMITH CLERK 800 20 30 SALES 7499 ALLEN SALESMAN 1600 30 10 ACCOUNTING 7782 CLARK MANAGER 2450 10 20 RESEARCH 7788 SCOTT ANALYST 3000 20 10 ACCOUNTING 7839 KING PRESIDENT 5000 10 20 RESEARCH 7902 FORD ANALYST 3000 20 10 ACCOUNTING 7934 MILLER CLERK 1300 10 40 OPERATIONS
2) RIGHT OUTER JOIN
RIGHT OUTER JOIN은 LEFT OUTER JOIN과 반대로 오른쪽 테이블을 기준으로 왼쪽 테이블에서 비교조건과 동일한 값을 가져와 붙여주는 형태의 작업이다. 동일한 값이 없다면 NULL이 붙는다.
SQL> SELECT * 2 FROM EMP RIGHT OUTER JOINDEPT 3 ON EMP.DEPTNO = DEPT.DEPTNO; EMPNO ENAME JOB SAL DEPTNO DEPTNO DNAME ------- --------- ----------- ------- --------- --------- ----------- 7369 SMITH CLERK 800 20 20 RESEARCH 7499 ALLEN SALESMAN 1600 30 30 SALES 7782 CLARK MANAGER 2450 10 10 ACCOUNTING 7788 SCOTT ANALYST 3000 20 20 RESEARCH 7839 KING PRESIDENT 5000 10 10 ACCOUNTING 7902 FORD ANALYST 3000 20 20 RESEARCH 7934 MILLER CLERK 1300 10 10 ACCOUNTING 40 OPERATIONS
3) FULL OUTER JOIN
FULL OUTER JOIN은 LEFT OUTER JOIN과 RIGHT OUTER JOIN을 모두 표현하는 것으로 왼쪽 테이블을 모두 나열하고 오른쪽 테이블도 모두 나열하여 비교조건이 없는 부분은 NULL로 처리한다.
SQL> SELECT * 2 FROM EMP FULL OUTER JOINDEPT 3 ON EMP.DEPTNO = DEPT.DEPTNO; EMPNO ENAME JOB SAL DEPTNO DEPTNO DNAME ------- --------- ----------- ------- --------- --------- ----------- 7369 SMITH CLERK 800 20 20 RESEARCH 7499 ALLEN SALESMAN 1600 30 30 SALES 7782 CLARK MANAGER 2450 10 7788 SCOTT ANALYST 3000 20 20 RESEARCH 7839 KING PRESIDENT 5000 10 7902 FORD ANALYST 3000 20 20 RESEARCH 7934 MILLER CLERK 1300 10 40 OPERATIONS
1.4 CROSS JOIN
- 조인 조건을 사용하지 않고 테이블을 하나로 조인 한다.
- 조인구가 없기 때문에 카테시안 곱이 발생 한다.
- 조인 결과의 행은 테이블 행을 곱한 값으로 5개 행과 6개 행 테이블은 30개의 결과 행이 된다.
- CORSS JOIN은 FROM 절에 “CROSS JOIN” 구를 사용하거나 “,”를 사용 하면 된다.
아래 쿼리는 동일 한 결과를 얻는다.
SELECT * FROM EMP, DEPT; -- WHERE 조건이 없는 것과 동일한 결과. SQL> SELECT * FROM EMP CROSS JOINDEPT; EMPNO ENAME JOB SAL DEPTNO DEPTNO DNAME ------ ---------- ----------- -------- --------- --------- ------------ 7369 SMITH CLERK 800 20 10 ACCOUNTING 7499 ALLEN SALESMAN 1600 30 10 ACCOUNTING 7782 CLARK MANAGER 2450 10 10 ACCOUNTING 7788 SCOTT ANALYST 3000 20 10 ACCOUNTING 7839 KING PRESIDENT 5000 10 10 ACCOUNTING 7902 FORD ANALYST 3000 20 10 ACCOUNTING 7934 MILLER CLERK 1300 10 10 ACCOUNTING 7369 SMITH CLERK 800 20 20 RESEARCH 7499 ALLEN SALESMAN 1600 30 20 RESEARCH 7782 CLARK MANAGER 2450 10 20 RESEARCH 7788 SCOTT ANALYST 3000 20 20 RESEARCH 7839 KING PRESIDENT 5000 10 20 RESEARCH 7902 FORD ANALYST 3000 20 20 RESEARCH 7934 MILLER CLERK 1300 10 20 RESEARCH 7369 SMITH CLERK 800 20 30 SALES 7499 ALLEN SALESMAN 1600 30 30 SALES 7782 CLARK MANAGER 2450 10 30 SALES 7788 SCOTT ANALYST 3000 20 30 SALES 7839 KING PRESIDENT 5000 10 30 SALES 7902 FORD ANALYST 3000 20 30 SALES 7934 MILLER CLERK 1300 10 30 SALES 7369 SMITH CLERK 800 20 40 OPERATIONS 7499 ALLEN SALESMAN 1600 30 40 OPERATIONS 7782 CLARK MANAGER 2450 10 40 OPERATIONS 7788 SCOTT ANALYST 3000 20 40 OPERATIONS 7839 KING PRESIDENT 5000 10 40 OPERATIONS 7902 FORD ANALYST 3000 20 40 OPERATIONS 7934 MILLER CLERK 1300 10 40 OPERATIONS
1.5 UNION을 사용한 합집함 구현
1) UNION
SELECT 결과들을 하나로 합치는 것이다.
SELECT 문의 COLUMN이 모두 동일 해야 UNION으로 합칠 수 있다.
UNION 연산은 중복된 SELECT 결과를 제거 한다.
UNION 연산은 SORT(정렬) 과정이 발생 한다.
2) UNION ALL
SELECT 결과들을 하나로 합치는 것은 UNION과 동일 하다.
UNION ALL은 중복된 결과를 제거하지 않고 정렬 과정도 발생하지 않는다.
1.6 MINUS (차집함)
먼저 조회한 SELECT의 결과에서 다음 SELECT의 결과에서 동일한 부분을 삭제 한다.
즉, 앞의 SELECT에는 있고 뒤의 SELECT에는 없는 집합을 조회 하는것.
- EXCEPT도 동일한 연산을 한다.
2. 계층형 조회 (Connect by)
- Oracle 데이터베이스에서 지원
- 계층형으로 데이터를 조회할 수 있다.
- START WITH구로 시작조건, CONNECT BY PRIOR 는 조인 조건이다.
- MAX(LEVEL)을 사용하여 최대 계층 수를 구할 수 있다.
SQL> SELECT MAX(LEVEL) 2 FROM EMPLOYEES 3 START WITH MANAGER_ID IS NULL 4 CONNECT BY PRIOR EMPLOYEE_ID = MANAGER_ID; MAX(LEVEL) ---------- 4
계층관계 즉 누가 각 직원의 메니져 인가를 구해 보면 MANAGER_ID 값이 NULL인 행이 최 상단 레벨 값(1)을 갖는다.
SQL> SELECT LEVEL, employee_id, manager_id, first_name 2 FROM EMPLOYEES 3 START WITH MANAGER_ID IS NULL 4 CONNECT BY PRIOR EMPLOYEE_ID = MANAGER_ID; LEVEL EMPLOYEE_ID MANAGER_ID FIRST_NAME ---------- ----------- ---------- ------------------------- 1 100 Steven 2 101 100 Neena 3 108 101 Nancy 4 109 108 Daniel 4 110 108 John 4 111 108 Ismael 4 112 108 Jose Manuel 4 113 108 Luis 3 200 101 Jennifer 3 203 101 Susan 3 204 101 Hermann
계층형 구조를 시각적으로 보기 위하여 LPAD 함수를 추가하여 들여쓰기를 해보면 좀더 잘자.
SELECT LEVEL, LPAD(' ', 4 + (LEVEL -1)) || employee_id AS "계층 구조", manager_id, CONNECT_BY_ISLEAF, first_name FROM EMPLOYEES START WITH MANAGER_ID IS NULL CONNECT BY PRIOR EMPLOYEE_ID = MANAGER_ID;
Connect by 키워드
키워드
설명
LEVEL
검색 항목의 깊이. 즉, 계층구조에서 가장 상위 레빌이 1이 된다.
CONNECT_BY_ROOT
계층구조에서 가장 최상위 값을 표시
CONNECT_BY_ISLEAF
계층구조에서 가장 최하위를 표시
SYS_CONNECT_BY_PATH
계층구조의 전체 전개 경로를 표시
NOCYCLE
순환구조가 발생지점 까지만 전개
CONNECT_BY_ISCYCLE
순환구조 발생 지점을 표시
3. SUBQUERY (서브쿼리)
3.1 Main Query (메인 쿼리)와 Subquery (서브 쿼리)
원래 조회하려는 SELECT 문을 사용하는 쿼리를 메인 쿼리라고 한다.
SELECT EMPNO, EMPNM FROM EMP WHRE EMPNO = ‘0001’;
메인 쿼리에 추가로 SELECT 나, FROM 또는 WHERE에 추가되는 SELECT 는 서브쿼리라 한다. Subquery는 SELECT 절, FROM 절, WHERE 절 어디에든 추가가 가능하다.
SELECT EMPNO, EMPNM, (SELECT ...) FROM EMP, (SELECT ...) WHRE EMPNO = 1000 AND ... (SELECT ...);
3.2 단일 행 서브쿼리와 다중 행 서브쿼리
- 반환되는 행의 수가 몇개 인가로 단일 행 서브쿼리, 멀티(다중) 행 서브쿼리로 분류한다.
서브쿼리 종류
설명
단일 행 서브쿼리 (Single Row Subquery
반환 행이 하나 비교 연산자(=, <,<=, >, >=, <>)를 사용.
다중 행 서브쿼리 (Multi Row Subquery)
반환 행이 여러 개 IN, ANY, ALL, EXISTS를 사용
3.3 다중 행 서브쿼리
다중 행 비교 연산자
다중 행 연산
설명
IN (Subquery)
(Subquery)의 결과 중 하나만 동일 하면 참
ALL (Subquery)
(Subquery)의 결과가 모두 동일하면 참 < ALL : 최소값을 반환 > ALL : 최대값을 반환
ANY (Subquery)
(Subquery)의 결과 중 하나 이상이 동일 하면 참
EXISTS (Subquery)
(Subquery)의 결과가 하나라도 존재하면 참
1) IN
Subquery가 반환하는 여러 개의 행 중에서 하나만 동일 해도 참이 되는 연산.
SQL> SELECT EMPNO, ENAME, SAL, DEPTNO 2 FROM EMP 3 WHERE SAL IN(SELECT SAL 4 FROM EMP 5 WHERE DEPTNO < 30); EMPNO ENAME SAL DEPTNO ------- ----------- ---------- ---------- 7369 SMITH 800 20 7782 CLARK 2450 10 7902 FORD 3000 20 7788 SCOTT 3000 20 7839 KING 5000 10 7934 MILLER 1300 10
SQL> SELECT SAL 2 FROM EMP 3 WHERE DEPTNO < 30; SAL ---------- 800 2450 3000 5000 3000 1300
2) ALL
Subquery의 결과가 모두 동일 하면 참.
SQL> SELECT EMPNO, ENAME, SAL, DEPTNO 2 FROM EMP 3 WHERE DEPTNO <= ALL(10, 20); EMPNO ENAME SAL DEPTNO ---------- -------------------- ---------- ---------- 7782 CLARK 2450 10 7839 KING 5000 10 7934 MILLER 1300 10
SQL> SELECT EMPNO, ENAME, SAL, DEPTNO 2 FROM EMP 3 WHERE DEPTNO <= ALL(20, 20); EMPNO ENAME SAL DEPTNO ---------- -------------------- ---------- ---------- 7369 SMITH 800 20 7782 CLARK 2450 10 7788 SCOTT 3000 20 7839 KING 5000 10 7902 FORD 3000 20 7934 MILLER 1300 10
3) EXISTS
Subquery에 결과 값의 존재 유무를 확인.
SQL> SELECT EMPNO, ENAME, DNAME 2 FROM EMP, DEPT 3 WHERE EMP.DEPTNO = DEPT.DEPTNO 4 AND EXISTS(SELECT 1 5 FROM EMP 6 WHERE SAL > 2000); EMPNO ENAME DNAME ---------- -------------------- ----------- 7369 SMITH RESEARCH 7499 ALLEN SALES 7782 CLARK ACCOUNTING 7788 SCOTT RESEARCH 7839 KING ACCOUNTING 7902 FORD RESEARCH 7934 MILLER ACCOUNTING
SQL> SELECT 1, SAL 2 FROM EMP 3 WHERE SAL > 2000; 1 SAL ---------- ---------- 1 2450 1 3000 1 5000 1 3000
4) Scala Subquery (스칼라 서브쿼리)
- Scala Subquery는 반드시 하나의 column 만 조회하고 결과도 하나의 행만 반환하는 쿼리.
- 여러 행이 반환(결과 값이 여러 개) 되면 오류가 발생 한다.
SQL> SELECT EMPNO, ENAME, 2 (SELECT AVG(SAL) 3 FROM EMP 4 ) AS "평균 급여" 5 FROM EMP 6 WHERE EMPNO = 7902; EMPNO ENAME 평균 급여 ---------- -------------------- ---------- 7902 FORD 2450
5) 연관 (Correlated Subquery)
- Subquery 내에서 Main Query의 column을 사용하는 것.
SQL> SELECT EMPNO, ENAME, 2 (SELECT DNAME 3 FROM DEPT 4 WHERE DEPTNO = EMP.DEPTNO 5 ) AS DEPTNM 6 FROM EMP 7 WHERE EMPNO = 7902; EMPNO ENAME DEPTNM ---------- -------------------- --------- 7902 FORD RESEARCH
4. 그룹 함수(GROUP FUNCTION)
4.1 ROLLUP
- GROUP BY에 사용되는 Column을 이용하여 Subtotal을 생성 한다.
- GROUP BY 구에 Column이 두 개 이상이면 순서에 따라 결과가 달라 진다.
SQL> SELECT DECODE(DEPTNO, NULL, '전체 합계', DEPTNO) AS DEPTNO, SUM(SAL) 2 FROM EMP 3 GROUP BY ROLLUP(DEPTNO); DEPTNO SUM(SAL) ---------- ---------- 10 8750 20 6800 30 1600 전체 합계 17150
SQL> SELECT DECODE(DEPTNO, NULL, '전체 합계', DEPTNO) AS DEPTNO, JOB, SUM(SAL) 2 FROM EMP 3 GROUP BY ROLLUP(DEPTNO, JOB); DEPTNO JOB SUM(SAL) ---------- ------------------ ---------- 10 CLERK 1300 10 MANAGER 2450 10 PRESIDENT 5000 10 8750 20 CLERK 800 20 ANALYST 6000 20 6800 30 SALESMAN 1600 30 1600 전체 합계 17150
ROLLUP에 JOB을 추가한 경우 JOB 컬럼에 null이 찍힌 이유는 동일한 DEPTNO에 대한 Subtotal값을 출력한 것이다.
4.2 GROUPING 함수
- ROLLUP, CUBE, GROUPING SETS에서 생성되는 합계 값을 구분하기 위해 만들어진 함수.
- 소계, 합계 등을 계산할 때 일반 ROW에는 0을 소계, 합계에는 1을 반환한다.
GROUPING(column)을 사용하면 바로 전에 소개한 [4.1 ROLLUP]에서 Subtotal이 NULL로 표시되었는데 GROUPING 함수를 사용하면 column을 기준으로 SUM에 대하여 1로 나타낸다.
SELECT WINDOW_FUNCTION(ARGUMENTS) OVER (PARTITION BY 컬럼 ORDR BY WINDOWING절) FROM 테이블명;
1) 윈도우 함수 구조
구조
설명
ARGUMENTS(인수)
윈도우 함수에 따라서 0~N개의 인수를 설정한다.
PARTITION BY
전체 집합을 기준에 의해 소그룹으로 나눈다
ORDER BY
어떤 항목에 대해서 정렬한다
WINDOWING
- 행 기준 범위를 정한다 - ROWS는 물리적 결과의 행 수이고 RANGE는 논리적인 값에 의한 범위이다.
2) WINDOWING
구조
설명
ROWS
부분집합인 윈도우 크기를 물리적 단위로 행의 집합을 지정한다.
RANGE
논리적 주소에 의해 행 집합을 지정한다.
BETWEEN~AND
윈도우의 시작과 끝 위치를 지정한다.
UNBOUNDED PRECEDING
윈도우 시작 위치가 첫 번째 행임을 의미한다
UNBOUNDED FOLLOWING
윈도우 마지막 위치가 마지막 행임을 의미한다.
CURRENT ROW
윈도우 시작 위치가 현재 행임을 의미한다. (데이터가 인출된 현재 행을 의미한다.)
SQL> SELECT DEPTNO, ENAME, SAL, 2 SUM(SAL) OVER (ORDER BY SAL 3 ROWS BETWEEN UNBOUNDED PRECEDING 4 AND UNBOUNDED FOLLOWING) TOTSAL 5 FROM EMP; DEPTNO ENAME SAL TOTSAL ---------- -------------------- ---------- ---------- 20 SMITH 800 17150 10 MILLER 1300 17150 30 ALLEN 1600 17150 10 CLARK 2450 17150 20 SCOTT 3000 17150 20 FORD 3000 17150 10 KING 5000 17150
SAL로 ORDER BY 하고 처음부터 끝까지 합한 결과를 TOTSAL로 조회 한다.
SQL> SELECT DEPTNO, ENAME, SAL, 2 SUM(SAL) OVER (ORDER BY SAL 3 ROWS BETWEEN UNBOUNDED PRECEDING 4 AND CURRENT ROW) TOTSAL 5 FROM EMP; DEPTNO ENAME SAL TOTSAL ---------- -------------------- ---------- ---------- 20 SMITH 800 800 10 MILLER 1300 2100 30 ALLEN 1600 3700 10 CLARK 2450 6150 20 SCOTT 3000 9150 20 FORD 3000 12150 10 KING 5000 17150
SAL로 ORDER BY 하고 처음부터 현재 행까지 합한 결과를 TOTSAL로 조회 한다.
5.2 순위 함수(RANK Function)
1) 순위 관련 윈도우 함수
순위 함수
설명
RANK
- 특정항목 및 파티션에 대해서 순위를 계산한다. - 동일한 순위는 동일한 값이 부여된다.
DENSE_RANK
- 동일한 순위를 하나의 건수로 계산한다.
ROW_NUMBER
- 동일한 순위에 대해서 고유의 순위를 부여한다.
- RANK : 동일한 순위는 동일한 값이 부여된다.
SQL> SELECT ENAME, JOB, SAL, 2 RANK() OVER (ORDER BY SAL DESC) ALL_RANK, 3 RANK() OVER (PARTITION BY JOB ORDER BY SAL DESC) JOB_RANK 4 FROM EMP; ENAME JOB SAL ALL_RANK JOB_RANK -------------------- ------------------ ---------- ---------- ---------- KING PRESIDENT 5000 1 1 SCOTT ANALYST 3000 2 1 FORD ANALYST 3000 2 1 CLARK MANAGER 2450 4 1 ALLEN SALESMAN 1600 5 1 MILLER CLERK 1300 6 1 SMITH CLERK 800 7 2
- ALL_RANK : SAL을 내림차순으로 정렬하고 순위를 부여하였다.
- JOB_RANK : SAL을 내림차순으로 정렬하고 동일한 JOB끼리 다시 순위를 부여 한다.
ANALYST는 SAL이 동일하니 모두 1순위. CLERK는 1300이 1순위, 800은 2순위
- DENSE_RANK : 동일한 순위를 하나의 건수로 계산한다.
SQL> SELECT ENAME, JOB, SAL, 2 RANK() OVER (ORDER BY SAL DESC) ALL_RANK, 3 DENSE_RANK() OVER (ORDER BY SAL DESC) DENSE_RANK 4 FROM EMP; ENAME JOB SAL ALL_RANK DENSE_RANK -------------------- ------------------ ---------- ---------- ---------- KING PRESIDENT 5000 1 1 SCOTT ANALYST 3000 2 2 FORD ANALYST 3000 2 2 CLARK MANAGER 2450 4 3 ALLEN SALESMAN 1600 5 4 MILLER CLERK 1300 6 5 SMITH CLERK 800 7 6
- ROW_NUMBER : 동일한 순위에 대해서 고유의 순위를 부여한다.
SQL> SELECT ENAME, JOB, SAL, 2 RANK() OVER (ORDER BY SAL DESC) ALL_RANK, 3 ROW_NUMBER() OVER (ORDER BY SAL DESC) ROW_NUM 4 FROM EMP; ENAME JOB SAL ALL_RANK ROW_NUM ------------ ------------ -------- ---------- ---------- KING PRESIDENT 5000 1 1 SCOTT ANALYST 3000 2 2 FORD ANALYST 3000 2 3 CLARK MANAGER 2450 4 4 ALLEN SALESMAN 1600 5 5 MILLER CLERK 1300 6 6 SMITH CLERK 800 7 7
5.3 집계함수(AGGREGATE FUNCTION)
집계 함수
설명
SUM
파티션 별로 합계를 계산한다.
AVG
파티션 별로 평균을 계산한다.
COUNT
파티션 별로 행 수를 계산한다.
MAX와 MIN
파티션 별로 최대값과 최소값을 계산한다.
SQL> SELECT ENAME, JOB, SAL, 2 SUM(SAL) OVER (PARTITION BY JOB) SUM_JOB 3 FROM EMP; ENAME JOB SAL SUM_JOB -------------------- ------------------ ---------- ---------- SCOTT ANALYST 3000 6000 FORD ANALYST 3000 6000 MILLER CLERK 1300 2100 SMITH CLERK 800 2100 CLARK MANAGER 2450 2450 KING PRESIDENT 5000 5000 ALLEN SALESMAN 1600 1600
같은 JOB을 가진 직원들의 급여를 합한 값을 보여준다.
5.4 행 순서 관련 함수
- 행 순서 관련 함수는 상위 행 값을 하위에 출력하거나 하위 행 값을 상위 행에 출력할 수 있다.
- 특정 위치의 행을 출력할 수 있다.
행 순서
설명
FIRST_VALUE
- 파티션에서 가장 처음에 나오는 값을 구한다. - MIN 함수를 사용해서 같은 결과를 구할 수 있다.
LAST_VALUE
- 파티션에서 가장 나중에 나오는 값을 구한다.
LAG
- 이전 행을 가지고 온다.
LEAD
- 윈도우에서 특정 위치의 행을 가지고 온다. - 기본값은 1이다.
- FIRST_VALUE
SQL> SELECT DEPTNO, ENAME, SAL, 2 FIRST_VALUE(ENAME) OVER (PARTITION BY DEPTNO 3 ORDER BY SAL DESC 4 ROWS BETWEEN UNBOUNDED PRECEDING 5 AND UNBOUNDED FOLLOWING) AS ENAME_A 6 FROM EMP; DEPTNO ENAME SAL ENAME_A ---------- -------------------- ---------- ------------------ 10 KING 5000 KING 10 CLARK 2450 KING 10 MILLER 1300 KING 20 SCOTT 3000 SCOTT 20 FORD 3000 SCOTT 20 SMITH 800 SCOTT 30 ALLEN 1600 ALLEN
부서로 파티션을 나누고 대상은 처음부터 마지막 행(BETWEEN...AND...)까지 선택하여, 급여가 가장 많은 직원으로 ORDER BY하여 처음에 나온 이름(제일 많은 급여를 받는)을 가져와 NAME_A에 출력 한다.
- LAST_VALUE
SQL> SELECT DEPTNO, ENAME, SAL, 2 LAST_VALUE(ENAME) OVER (PARTITION BY DEPTNO 3 ORDER BY SAL DESC 4 ROWS BETWEEN UNBOUNDED PRECEDING 5 AND UNBOUNDED FOLLOWING) AS ENAME_A 6 FROM EMP; DEPTNO ENAME SAL ENAME_A ---------- -------------------- ---------- -------------------- 10 KING 5000 MILLER 10 CLARK 2450 MILLER 10 MILLER 1300 MILLER 20 SCOTT 3000 SMITH 20 FORD 3000 SMITH 20 SMITH 800 SMITH 30 ALLEN 1600 ALLEN
부서로 파티션을 나누고 대상은 처음부터 마지막 행(BETWEEN...AND...)까지 선택하여, 급여가 가장 많은 직원으로 ORDER BY하여 마지막에 나온 이름(제일 적은 급여를 받는)을 가져와 NAME_A에 출력 한다.
- LAG
SQL> SELECT DEPTNO, ENAME, SAL, 2 LAG(SAL) OVER (PARTITION BY DEPTNO 3 ORDER BY SAL DESC) AS LAG_SAL 4 FROM EMP; DEPTNO ENAME SAL LAG_SAL ---------- -------------------- ---------- ---------- 10 KING 5000 10 CLARK 2450 5000 10 MILLER 1300 2450 20 SCOTT 3000 20 FORD 3000 3000 20 SMITH 800 3000 30 ALLEN 1600
Lag 함수는 이전 행의 값을 가지고 오는 함수로 바로 이전 행의 SAL 값을 출력 하며 DEPTNO로 파티션을 나누어서 SCOTT의 경우는 자신이 최초의 값으로 이전 값을 가져올 수 없다. PARTITION을 제외하여 이전 값을 가져오도록 해보자.
SQL> SELECT DEPTNO, ENAME, SAL, 2 LAG(SAL) OVER ( 3 ORDER BY SAL DESC) AS LAG_SAL 4 FROM EMP; DEPTNO ENAME SAL LAG_SAL ---------- -------------------- ---------- ---------- 10 KING 5000 20 SCOTT 3000 5000 20 FORD 3000 3000 10 CLARK 2450 3000 30 ALLEN 1600 2450 10 MILLER 1300 1600 20 SMITH 800 1300
파티션 구분 없이 SAL로 정렬하여 KING을 제외하고 모두 이전 값을 가지고 온다.
- LEAD
SQL> SELECT DEPTNO, ENAME, SAL, 2 LEAD(SAL, 3) OVER (ORDER BY SAL DESC) AS LEAD_SAL 3 FROM EMP; DEPTNO ENAME SAL LEAD_SAL ---------- -------------------- ---------- ---------- 10 KING 5000 2450 20 SCOTT 3000 1600 20 FORD 3000 1300 10 CLARK 2450 800 30 ALLEN 1600 10 MILLER 1300 20 SMITH 800
LEAD는 현재 행에서 몇 번째 아래에 있는 값을 가지고 오는 것으로 여기서는 3번행 아래에 있는 값을 가지고 오도록 하였다. ALLEN, MILLER, SMITH는 3번째 아래에는 아무것도 없으니 값을 가지고 오지 못한다.
5.5 비율 관련 함수
비율 함수
설명
CUME_DIST
- 파티션 전체 건수에서 현재 행보다 작거나 같은 건수에 대한 누적 백분율을 조회한다. - 누적 분포상에 위치를 0~1사이의 값을 가진다.
PERCENT_RANK
파티션에서 제일 먼저 나온 것을 0으로 제일 늦게 나온 것을 1로 하여 값이 아닌 행의 순서 별 백분율을 조회한다.
NTILE(ARGUMENT)
파티션 별로 전체 건수를 ARGUMENT 값으로 N등분한 결과를 조회한다.
RATIO_TO_REPORT
파티션 내에 전체 SUM(칼럼)에 대한 행 별 칼럼 값의 백분율을 소수점까지 조회한다.
- CUME_DIST
SQL> SELECT DEPTNO, ENAME, SAL, 2 CUME_DIST() OVER (PARTITION BY DEPTNO 3 ORDER BY SAL) AS CUME_SAL 4 FROM EMP; DEPTNO ENAME SAL CUME_SAL ---------- -------------------- ---------- ---------- 10 MILLER 1300 .333333333 10 CLARK 2450 .666666667 10 KING 5000 1 20 SMITH 800 .333333333 20 SCOTT 3000 1 20 FORD 3000 1 30 ALLEN 1600 1
DEPTNO로 파티션을 나누고 자신보다 작거나 같은 급여를 받는 비율을 구하는 것으로 MILLER는 DEPTNO 10에서 자신보다 급여가 같거나 작은 사람은 혼자이고 비율은 33%, CLARK는 자신보다 급여가 같거나 작은 사람이 3명 중 2명으로 66%가 된다.
- PERCENT_RANK
SQL> SELECT DEPTNO, ENAME, SAL, 2 PERCENT_RANK() OVER (PARTITION BY DEPTNO 3 ORDER BY SAL DESC) AS PER_SAL 4 FROM EMP; DEPTNO ENAME SAL PER_SAL ---------- -------------------- ---------- ---------- 10 KING 5000 0 10 CLARK 2450 .5 10 MILLER 1300 1 20 SCOTT 3000 0 20 FORD 3000 0 20 SMITH 800 1 30 ALLEN 1600 0
PERCENT_RANK 함수는 파티션에서 등수의 퍼센트를 구하는 것이다. 1등은 0, 꼴등은 1로 설정을 하며 DEPTNO가 20인 경우 SCOTT, FORD는 급여 등수가 동일 하므로 둘 다 0을 갖는다.
- NTILE
SQL> SELECT DEPTNO, ENAME, SAL, 2 NTILE(3) OVER ( 3 ORDER BY SAL DESC) AS PRE_SAL 4 FROM EMP; DEPTNO ENAME SAL PRE_SAL ---------- -------------------- ---------- ---------- 10 KING 5000 1 20 SCOTT 3000 1 20 FORD 3000 1 10 CLARK 2450 2 30 ALLEN 1600 2 10 MILLER 1300 3 20 SMITH 800 3
NTILE(3)은 급여가 높은 순으로 1~3등분으로 분할한다. 급여가 가장 높은 등급에 속하면 1, 가장 낮은 등급에 속하면 3이 된다.
- RATIO_TO_REPORT
SQL> SELECT DEPTNO, ENAME, SAL, 2 RATIO_TO_REPORT(SAL) OVER () AS RATIO_SAL, 3 SUM(SAL) OVER() AS SUM_SAL, 4 SAL/SUM(SAL) OVER() AS SAL_PER 5 FROM EMP; DEPTNO ENAME SAL RATIO_SAL SUM_SAL SAL_PER -------- --------- ------ ---------- ---------- ---------- 20 SMITH 800 .04664723 17150 .04664723 30 ALLEN 1600 .093294461 17150 .093294461 10 CLARK 2450 .142857143 17150 .142857143 20 SCOTT 3000 .174927114 17150 .174927114 10 KING 5000 .29154519 17150 .29154519 20 FORD 3000 .174927114 17150 .174927114 10 MILLER 1300 .075801749 17150 .075801749
RATIO_TO_REPORT는 해당 컬럼의 총 합계에서 백분률을 구하는 것으로 실제 SUM을 구하고 SAL/SUM(SAL)을 사용한 방법과 비교를 해 보았다.
6. 테이블 파티션(Table Partition)
6.1 Partition 기능
- 대용량의 테이블 또는 인덱스 데이터를 파티션(Partition) 단위로 나누어 저장하는 것